
We'll look at how to use alignment grouping and enumeration grouping in esProc through the following example.
1. Alignment grouping
Database table LIQUORS has information of some wines:
But how can we group these wines by
varieties in the order of Vodka, Gin, Rum, Whisky, Brandy, Tequila and Cordial?
We can manage it easily in esProc with P.align@a() function:

Among these results, each group is made up
of records in A1. Double-click to see more.

Seen from the computed results of A3, alignment grouping will only put records to the first eligible group and make the last group an empty one:

esProc's P.align() function
provides many options that can manage various situations in alignment
operations.
If @n is used by P.align@a() function, a new group for
taking all the ungrouped records will appear except those designated ones.
Because @n option is only
used in alignment grouping operations, here @a can be omitted:
Computed results of A3 are as follows:


Computed results of A3 are:

If @p option is used by P.align@a() function,groups won't store records except their sequence numbers:

Computed results of
A3 are:
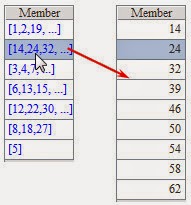
It can be seen that only sequence number
of each record is stored in the group.

Now the computed results of A3 are as follows:

Note that when @s option is at work, it is invalid to introduce @a option at the same time.


While A4 doesn't execute sorting of A2, so the results of alignment grouping are incorrect when @a option and @b option are used simultaneously:
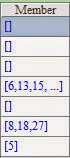

Because the places have been directly set, the specific value of each member in grouping value sequence of align function won't affect the result, and we can use the simplest sequence to(n) to complete alignment grouping according to the number of groups. Here to(n) can be abbreviated to n. Expressions in A3 and A4 have the same computed results:

If @r option is used by P.align@a(n,y) function, each record will correspond to a sequence of group numbers and can be put into more than one group. Such as:

Computed results of A3 are:

P.align() function can manage more complicated jobs through
combinations of its options.
2.Enumeration grouping
Enumeration grouping is, in fact, a type
of alignment grouping. Its alignment basisis the computed results of designated
expressions.
For example, divide the wine information
in table LIQUORS into three groups by
names: ?<"D",?<"K", and ?>="K". First create a
sequence according to the conditions, then execute enumeration grouping on all
information of wines by using P.enum() function according to the
condition sequences:

Computed results of A3 are:
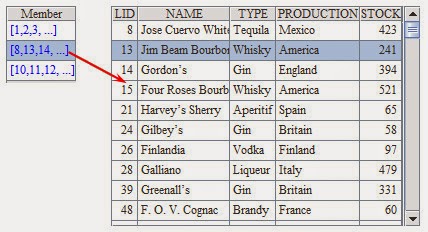
By default, records of P only appear once when P.enum() function
is used for grouping. It can be noticed that the grouping condition of the
second group is ?<"K",
and though the records in the first group satisfy this condition, they won't
appear again in the second group.
Various options can be used by enum function to realize its different
functions.
If @r option is used by P.enum() function, the same records are allowed to appear in more than one groups:

Computed results of A3 are as follows:

It can be seen that, for the time being,
the second group contains all eligible records, including those in the first
group.

Now the computed results of A3 are as follows:

It can be seen that each group stores only
the corresponding record numbers.

Results of A3 are as follows:

No comments:
Post a Comment