
1.Comparison of basic functions
Description:There are six columns in sales.txt, they are separated from each other by tab \t. Lines are separated from each other by line break\n. The first row contains column names. Read the file into the memory and write it anew. The first rows of the file are as follows:

esProc:
data=file("e:\\sales.txt").import@t()
file("e:\\salesResult.txt").export@t(data)
R language:
data<-read.table("e:\\sales.txt",sep="\t", header=TRUE)
write.table(data, file="e:\\ salesResult.txt",sep="\t",quote=FALSE,row.names=FALSE)
Comparison:
1.Both esProc and R language can do this job conveniently. esProc uses function option "@t"to represent that the first row contains column names, while R language uses "header=TURE" to do the same thing.
2. Line breaks are the most common separators for separating lines from each other. Both esProc and R language support line breaks by default. And tabs are the most common separators for separating columns from each other. esProc supports tabs by default. If other types of separators like comma are designated to be used, the code should be import@t(;",").In R language, default column separators are "blanks and tabs", which can mistakenly separate the Client column containing blanks into two columns, thus sep="\t" is needed to define separators as tabs. In addition, "quote=FALSE,row.names=FALSE" in the code represents that it is not necessary to put elements in quotes and to output row number.
3.Usually, files read into the memory will be stored as structured two-dimensional data objects, which are called table sequence(TSeq) in esProc or data frame (data.frame) in R language. Both TSeq and data.frame have rich computational functions. For example,group by Client and SellerID, then sum upAmount and find maximum. The code for esProc to perform the computations is:
1.Both esProc and R language can do this job conveniently. esProc uses function option "@t"to represent that the first row contains column names, while R language uses "header=TURE" to do the same thing.
2. Line breaks are the most common separators for separating lines from each other. Both esProc and R language support line breaks by default. And tabs are the most common separators for separating columns from each other. esProc supports tabs by default. If other types of separators like comma are designated to be used, the code should be import@t(;",").In R language, default column separators are "blanks and tabs", which can mistakenly separate the Client column containing blanks into two columns, thus sep="\t" is needed to define separators as tabs. In addition, "quote=FALSE,row.names=FALSE" in the code represents that it is not necessary to put elements in quotes and to output row number.
3.Usually, files read into the memory will be stored as structured two-dimensional data objects, which are called table sequence(TSeq) in esProc or data frame (data.frame) in R language. Both TSeq and data.frame have rich computational functions. For example,group by Client and SellerID, then sum upAmount and find maximum. The code for esProc to perform the computations is:
data.groups(Client,SellerId;sum(Amount),max(OrderID))
As data.frame doesn’t directly support simultaneous use of multiple aggregation methods, two steps are needed to sum up and find maximum. Finally, cbind will be used to combine the results. See below:
result1<-aggregate(data[,4],data[c(2,3)],sum)
result2<-aggregate(data[,1],data[c(2,3)],max)
result<-cbind(result1,result2[,3])
4. Except storing files as the structured two-dimensional data objects in the memory, esProc can access files by cursor objects. While R language can access files by matrix objects.
Conclusion:For basic file reading and writing, both esProc and TSeq provide rich functions to meet users' needs.
2.Reading files with fixed column width
In some files, fixed width, instead of separators, is used to differentiate one column from another. For example, read file static.txt which contains three columns of data into the memory and modify column names respectively to col1, col2 and col3, among which the width of col1 is 1, that of col2 is 4 and that of col3 is 3.
A1.501.2
A1.551.3
B1.601.4
B1.651.5
C1.701.6
C1.751.7
esProc:
data=file("e:\\static.txt").import()
data.new(mid(_1,1,1):col1, mid(_1,2,4):col2, mid(_1,6,8):col3)
R language:
data<-read.fwf("e:\\sales.txt ", widths=c(1, 4, 3),col.names=c("col1","col2","col3"))
Comparison:
R language does this job directly while esProc does it indirectly by reading the file into the memory first and split it into multiple columns. Note that in the code mid(_1,1,1), “_1” represents default column names, and if the file read into the memory has more than one column, the default column names will be in due order: _1、_2、_3 and so on.
Conclusion:R language is more convenient than esProc because it can read files with fixed column width.
3.Reading and writing designated columns
Sometimes only some of the data columns are needed in order to save memory and enhance performance. In this example, read columns ORDERID, CLIENT and AMOUNT into the memory and write ORDERID and AMOUNT to a new file.esProc:
data=file("e:\\sales.txt").import@t(ORDERID,CLIENT,AMOUNT)
file("e:\\salesResult.txt").export@t(data,ORDERID,AMOUNT)
R language:
data<-read.table("e:\\sales.txt",sep="\t", header=TRUE)
col3<-data[,c(“ORDERID”,”CLIENT”,”AMOUNT”)]
col2<-col3[,c(“ORDERID”,”AMOUNT”)]
write.table(col2, file="e:\\ salesResult.txt", sep="\t",quote=FALSE,row.names=FALSE)
Comparison:
esProc does the job directly, while R language does it indirectly by reading all columns into the memory and saving designated columns in a new variable.
Conclusion:
R language can only read all columns into the memory, which will occupy a relatively large memory.
4.Processing big text files
Big text files are files whose sizes are bigger than memory size. Usually they are processed by reading and computing in batches. For example, in big text file sales.txt, filter data according to the condition Amount>2000 and sum up Amount of each SellerID.
esProc:

A1: As reading the big text file into the memory at a time will result in memory overflow, it will be read in batches with cursor.
A2: Read by loop with 100,000 rows of data each time and store them in TSeq A2.
B3: Among each batch of data, filter out records whose order amount is greater than 2,000.
B4: Group and summarize the filtered data, and seek each seller's sales amount in this batch.
B5: Append the computed results of this batch to a certain variable (B1), and begin the computation of the next batch.
B6: After the computations all batches are over, each seller's sales amount of each batch can be found in B1, execute another and the last grouping and summarizing to get the total sales amount of each seller.
R language:

1-4:Create an empty data frame data to generate each batch's data frame databatch.
5-9:Create an empty data frame agg to append the results of grouping and summarizing of each batch.
11-13:Read in the file by rows, with 100,000 lines each time, but skip the column names of the first row.
15-21:In each batch of data, filter out records whose order amount is greater than 2,000.
22:Group and summarize the filtered data, and seek each seller’s sales amount of this batch.
23:Append the computed results of this batch to a certain variable (agg), and begin the computation of next batch.
24:After the computations of all batches are over, each seller's sales amount of each batch can be found in B1, execute another and the last grouping and summarizing to get the total sales amount of each seller.
Comparison:
1. Both of them have the same way of thinking. Differences are that esProc does the job with library function and its code is concise and easy to understand, while R language needs to process a great deal of details manually and its code is lengthy, complicated and error-prone.
2 .With esProc cursor, the above computations can be performed more easily, that is:

In this piece of code, esProc engine can automatically process data in batches, and it is not necessary for programmers to control manually by loop statements.
Conclusion:In processing big text files, esProc code is more concise, more flexible and easier to understand than that of R language.
5.Processing big text files in parallel
Parallel computing can make full use of the resource of multi-core CPU and significantly improve computational performance.The example in the above part is still used here, but parallel computing is used. That is, divide sales.txt into four segments to give four CPU cores to perform computations, then filter data according to the condition Amount>2000 and compute the total sales amount of each seller.
esProc:
Main program(pro5.dfx)
Main program(pro5.dfx)
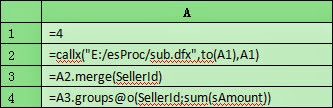
A1:Set the number of parallel tasks as four, meaning the file would be divided into four segments.
A2:Call subprogram to perform multi-threaded parallel computing, and there are two task parameters: to(A1) and A1. Value of to(A1) is [1,2,3…24], representing segment number assigned to each task; A1 is the total number of segments. When all the tasks are completed, all computed results will be stored in the current cell.
A3:Merge the computed results of every task in A2 according to SellerID.
A4:Group and summarize the merge results and seek each seller's sales amount.
Subprogram(sub.dfx)

A1: Read the file with cursor, and decide which segment of the file the current task should process according to the parameter sent by the main program. Take the third task as an example, value of the parameter segment is 3 and that of parameter total is always 4.
A2: Select records whose order amount is greater than 2,000.
A3: Group and summarize the filtered data.
A4: Return the computed results of current task to main program.
R language:It cannot do this job by using parallel computing.
Comparison:
esProc can read big text files segmentally by bytes, and designated part by skipping useless data and supporting multi-threaded parallel computing in the low level.
Though R language can perform parallel computing of in-memory data, it cannot read files in disk segmentally by bytes. It can also read data by skipping multiple rows, but this method has to traversal all useless data, resulting in poor performance and inability to perform parallel computing of big text files in the low level.
In addition, esProc can automatically manage the situation that there is only half line of data when segmenting by bytes, as shown in the above code, thus it is unnecessary for programmers to handle it manually.
Summary:
esProc can process big text files in parallel and has a high computational performance. R language cannot perform the parallel computing of big text files in the low level and has a much poorer performance.
6.Computational performance
Under the same test circumstance, use esProc and R language to read a file of 1G size, and summarize one of the fields.esProc:
=file("d:/T21.txt").cursor@p(#1:long)
=A1.groups(;sum(#1))
R language:
con<- file("d:/T21.txt", "r")
lines=readLines(con,n=1024)
value=0
while( length(lines) != 0) {
for(line in lines){
data<-strsplit(line,'\t')
value=value+as.numeric(data[[1]][1])
}
lines=readLines(con,n=1024)
}
print(value)
close(con)
Comparison:
1. It takes esProc 26 seconds and R language 9 minutes and 47 seconds respectively to finish the task. Their gap exceeds an order of magnitude.
2..In processing big files, R language cannot use data frame objects and library function. It can only write loop statements manually and compute while the file is being read, so the performance is poor. esProc can directly use cursor objects and library function and has a higher performance. But there is no big difference between them when processing small files.
1. It takes esProc 26 seconds and R language 9 minutes and 47 seconds respectively to finish the task. Their gap exceeds an order of magnitude.
2..In processing big files, R language cannot use data frame objects and library function. It can only write loop statements manually and compute while the file is being read, so the performance is poor. esProc can directly use cursor objects and library function and has a higher performance. But there is no big difference between them when processing small files.
Summary: esProc's performance is far beyond that of R language in processing big text files.
No comments:
Post a Comment