
During developing the database applications, we often need to
perform computations on the grouped data in each group. For example, list the
names of the students who have published papers in each of the past three
years; make statistics of the employees who have taken part in all previous
training; select the top three days when each client gets the highest scores in
a golf game; and the like. To perform these computations, SQL needs multi-layered
nests, which will make the code difficult to understand and maintain. By
contrast, esProc is better at handling this kind of in-group computation, as
well as easy to integrate with Java and the reporting tool. We’ll illustrate this
through an example.
According to the database table SaleData,
select the clients whose sales amount of each month in the year 2013 is always
in the top 20. Part of the data of SalesData
is as follows:

To complete the task, first select the sales data of the year of 2013,
and then group the data by the month and, in each group, select the clients
whose monthly sales amount is in the top 20. Finally, compute the intersection of
these groups.

Note: The code for filtering in A2 can also be written in SQL.

esProc will sorts the data automatically before grouping. Each group is a set of sales data. The data of March, for example, are as follows:

In order to compute every client‘s sales amount of each month, we
need to group the data a second time by clients. In esProc, we just need to
perform this step by looping the data of each month and group it respectively. A.(x) can be used to execute the loop on members of a certain group,
with no necessity for loop code.
A4:=A3.(~group(Client))
In A4, the data of each month constitute a subgroup of each previous
group after the second grouping:
At this point, the data of March are as follows:
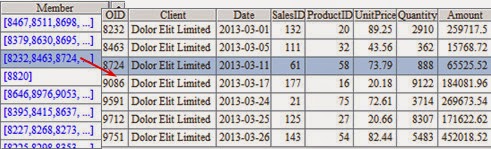
It can be seen that each group of data in March contains the sales
data of a certain client.
Please note "~" in the above code represents each member of the
group, and the code written with “~” is called in-group computation code, like
the above-mentioned ~.group(Client).
Next, select the clients whose rankings of each month are in the top
20 through the in-group computation:
A5:=A4.(~.top(-sum(Amount);20))
A6:=A5.(~.new(Client,sum(Amount):MonthAmount))
A5 computes the top 20 clients of each month in sales amount by looping each month's data. A6 lists the clients and their sales amount every month. The result of A6 is as follows:

Finally, list the field Client
of each subgroup and compute the intersection of the subgroups:
A7:=A6.(~.(Client))
A8:=A7.isect()
A7 computes the top 20 clients of each month in sales amount. A8 computes the intersection of the field Clients of the twelve months. The result is as follows:

As can be seen from this problem, esProc can easily realize the
in-group computation, including the second group and sort, on the structured
data, make the solving way more visually, and display a clear and smooth data
processing in each step. Moreover, the operations, like looping members of a
group or computing intersection, become easier in esProc, which will reduce the
amount of code significantly.
The method with which a Java program calls esProc is similar to that
with which it calls an ordinary database. The JDBC provided by esProc can be
used to return a computed result of the form of ResultSet to Java main program. For more details, please refer to
the related documents
No comments:
Post a Comment