
During developing database applications, we are often faced with
complicated SQL-style computations like relational computation on multilayered
groups. As SQL requires summarizing during data grouping and it doesn't support
object-style relational access, it is difficult to deal with these
computations. We have to resort to an advanced technique of window functions
nested with multilayered subqueries. esProc, however, can handle them more
easily by supporting real grouping and visual object-style relational access.
In practice, there are a lot of cases in which relational
computation on groups is needed, such as the one presented on the website http://forums.bit-tech.net/showthread.php?t=207052. Based on this practical example, we have designed a more
common one for illustrating in detail how esProc works to realize the
relational computation on groups.
Computing target: Query branches of a DVD store where there are less than four categories
of DVD copies.
Data Structure:Branch Table stores information of
the branch stores. DVD Table stores titles and categories of DVDs, in which
DVDs, like Transformers IV, are
virtual data items instead of physical disks. DVDCopy Table stores physical DVD
copies branch stores have. Note: DVDCopy Table is related to Branch Table
through BranchID field, and to DVD Table through DVDID field. The following is
part of the data:
Branch Table:


DVDCopy Table:

Description:
1.Computed results should be
certain records in Branch Table.
2.That the Status field of a record in DVDCopy shows Miss means the DVD is
missing, and that a record’s LastDateReturned
field is empty means the DVD has been rented out but not returned. Obviously
the DVDs that are missing and haven't been returned are outside of our
computing objects and should be filtered away.
3.We should consider the
situation that there may be certain branch stores whose information isn't
included in DVDCopy Table, though it is rarely seen.
Solution:
1.Select valid, existing DVD
copies the branch stores have from DVDCopy Table.
2.Group DVDCopy Table by BID. Each group will contain all DVD
copies a branch store has.
3.Select the DVDs corresponding
to the DVD copies each branch store has, and compute the number of categories
to which these DVDs belong.
4.Select branch stores where the
number of categories of existing DVDs is less than four. These branch stores
are eligible.
5.Select branch stores which
DVDCopy Table hasn't. They are also eligible.
6. Combine the two kinds of
eligible branch stores.

A1-A3:Query data from three tables in the database. The three tables are made variables which are named respectively as Branch, DVD and DVDCopy. Computed results are as follows:

A4: Switch the DVDID field and BID field in DVDCopy Table to corresponding records in DVD Table and Branch Table respectively. Note: This step is the basis of object-style relational access, which requires the use of switch function. After computing, DVDCopy becomes as follows:

Fields in blue have corresponding records. Click one and you can see the details, as shown in the following figure:

Now we can perform object-style relational access only with the
operator “.”. For instance, DVDCopy.(DVDID). (Category)
represents the category of each DVD copy, and DVDCopy.(BID)
gets the detailed information (complete record) about the branch store
corresponding to each DVD copy.

A6:=A5.group(BID) is to group data in A5 by BID, with each row representing all DVD copies a branch store has. The result is as follows:

Click the data in blue and you’ll see members of each group:

It can be seen that group
function only groups data, but doesn't summarize the data at the same time. In
this point, it is different from the function for grouping in SQL. Sometimes,
we need to further process the grouped data, rather than simply summarizing
them. To do this, esProc's group
function is more convenient to use, as shown in the code in A7:
A7:=A6.new( ~.BID:BonList,
~.(DVDID).id(Category).count():CatCount )
The above line of code computes the number of categories of DVD
copies to which each branch store corresponds. new function can generate a new object A7 based on the data in A6.
A7 has two columns: BonList and CatCount. BonList originates directly from
column BID of the grouped data in A6, and CatCount originates from column DVDID
of the grouped data. There are three steps to compute CatCount: ~.(DVDID) finds the DVD records corresponding to
all DVD copies each branch store has; id(Category) removes
repeated records of Category from these DVD records; and count() computes the number of categories. The
result is as follows:
That is, branch store B002 has three categories of DVD copies, B003
also has three categories and B001 has four categories.

The above branch stores that are in short supply are computed
according to DVDCopy Table. But maybe some branch stores
with serious supply shortage are not in the DVDCopy, such as the cases that all
the DVD copies in the branch store has been rented out, or that the branch
store hasn't any DVD copies. So these branch stores should also be counted. The
code for this step is as follows:
A9:=A8.(BonList) |
(Branch \ A7.(BonList))

A9 computes the final result of this example. Its values are:
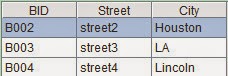
Or we can realize the computation indirectly. For instance, first
compute "branch stores that are not in short supply", and then compute the
complement of the result and Branch Table. The final result should be the same
as that of A9.
Please note variables like A8 or Branch cannot be used to represent
a data set in SQL because it doesn't support explicit set. Thus the simple code
in the above have to be replaced by lines of complicated SQL statements.
Besides, esProc can be called by a Java program. The method is
similar to that with which a Java program calls an ordinary database. The JDBC
provided by esProc can be used to return a computed result of the form of ResultSet to Java main program. For more
details, please refer to the related documents
No comments:
Post a Comment