
It is difficult to handle operations involving heterogeneous or multiple datasources, such as joins across MongoDB and MySQL, using the reporting tool, like Jasper Report, alone. Indeed Jasper Report and BIRT have the virtual data source or the table join and other functions to deal with them, but the functions are only provided in commercial or higher versions – because it’s hard to be provided for free – and have limited ability. They don’t support subsequent structured data computing on the joined data as SQL does.
esProc has a powerful structured data computing engine, supports heterogeneous datasources and is easy to be integrated. It is useful in assisting the reporting tool to realize joins across MongoDB and MySQL conveniently. Learn how esProc operates through the following example.
emp1 is a collection in MongoDB and cities is a table in MySQL. emp1’s CityID field, equivalent to a foreign key logically, points to cities’s CityID field. CityID and CityName are two fields of cities. What we want is to select employees from emp1according to a specified time interval and switch its CityID to CityName. Some of the source data are as follows:

Table cities

esProc script:

A1=MongoDB("mongo://localhost:27017/test?user=root&password=sa")
This line of code establishes the connection to MongoDB, in which user and password are parameters for specifying the user name and the password.
esProc supports to connect to MongoDB through JDBC as it does to connect to an ordinary database. But because the third-party JDBC is not as powerful as the official library function – for example, it cannot retrieve multilayer data, esProc encapsulates native methods directly, to retain MongoDB’s functions and syntax. Thus find function can be used.
A2=A1.find("emp1","{'$and':[{'Birthday':{'$gte':'"+string(begin)+"'}},{'Birthday':{'$lte':'"+string(end)+"'}}]}","{_id:0}").fetch()
This line of code retrieves records during a certain time interval from collection emp1 in MongoDB. find function’s first parameter is the collection name, its second parameter is the query condition that is defined according to syntax of MongoDB, and its third one is the specified field to be returned. Query condition’s two parameters- begin and end – are external parameters passed from the reporting tool, specifying respectively the beginning time and the ending time for Birthday.
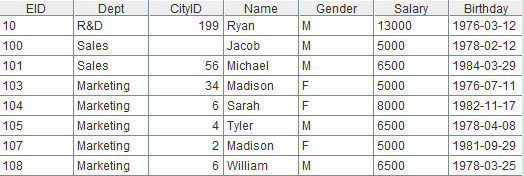
find function returns a cursor. That means it won’t load all data into the memory at once and thus supports big data processing. The result cursor can be further processed by functions such as skip, sort, conj and etc. And data won’t be fetched until fetchfunction, groups function or for statement come into play. Suppose the time interval is from 1976-01-01 to 1988-12-31, then result of A2 is this:
A3=A1.close()
This line of code is used to close the connection to MongoDB established in A1.
A4=myDB1.query("select * from cities")
This line of code executes an SQL statement for retrieving data from MySQL, in which myDB1 is the datasource name. The configuration interface is as follows:

It can be seen that the connection to the datasource is established through JDBC, which supports any database. In this way, the connection can be established and close either automatically or manually. Connection to MongoDB uses the latter way while this case adopts the former.
query function makes query through an SQL statement. Result is as follows:

A5=A2.switch(CityID,A4)
This line of code replaces A2’s CityID field with A4’s corresponding records, with an effect similar to the left join. After the switching, A2 becomes like this (both A2 and A5 points to the same two-dimensional table):


Sometimes if an inner join is needed, use @i option in switch function. Then the code will be A2.switch@i(CityID,A4) and the result is as follows:

A6=A5.new(EID,Dept,CityID.CityName:CityName,Name,Gender)
A5 establishes a relation between the collection and the table, while A6 retrieves from the result data the fields we want and creates a two-dimensional table using new function. CityID.CityName:CityName means retrieving CityName field corresponding to CityID field from A5 and renaming it CityName (for the reporting tool cannot identify field names like CityID.CityName).
As can be seen from the above code, after fields are switched by switch function, the database relation can be represented through object type access. This is simple and more intuitive, especially when establishing the multi-table and multilayer relation.
Result of A6 is as follows:

That is all the data needed for creating the report. The final step is to return A6’s two-dimensional table to the reporting tool using result A6. esProc offers JDBC interface to be integrated with the reporting tool and the latter will identify it as a database. Learn more about the integration solution in related documents.

Define two parameters – Pbegin and Pend – corresponding to the two esProc parameters in the report. Click Preview to see the report:

No comments:
Post a Comment