
After data are imported from a data table, they are usually grouped as
required and grouping and summarizing result is needed to be worked out. In
esProc, groups function is used to compute the result of data grouping and
summarizing; or the function will first group the data, then further analysis
and computation are to be performed later.
But the case will be different in processing huge data, for the
records cannot be loaded to the memory all together and distributed into each
group. Other times the number of groups is huge and the grouping and
summarizing result cannot even be returned all at once. In these two occasions,
the external memory grouping is
required.
1. Grouping with cursor by directly specifying group numbers
Let's create a big, simple data table containing employee
information, which includes three fields: employee ID, state and birthday. The
serial numbers are generated in order and the states are written in their abbreviated forms obtained
arbitrarily from the STATES table of
demo database; birthdays are the
dates selected arbitrarily within 10,000 days before 1994-12-31.The
data table will be stored as a binary file for convenience.

Altogether 1,000,000 rows of data are generated. The result of reading the 50,001th ~51,000th rows of data with cursor can be seen in C10 as follows:
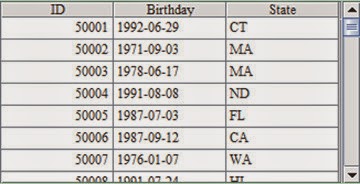
In the following, we'll take the generated data file, BirthStateRecord, as an example to explore how to group in cursor computing by directly specifying group numbers. Because the data of the big data table cannot be loaded all together into the memory, we cannot perform grouping on it as we do on an ordinary table sequence. To solve this problem, esProc offers cs.groupx(x) function which can distribute the records in cursor cs according to the computed result of expression x into groups with specified serial numbers and return the sequence of cursor. For example:

To explain the way in which cs.groupx(x) function performs grouping by using external memory to specify group numbers, the code will be executed step by step by clicking
While the code in A5 is executed, external files are generated in the directory of temporary files:

In the operation of groupx function, the number of temporary files equals that of the groups of records. We can import data from one of the temporary files:

The data A2 imports are as follows:

It can be seen that the data of a temporary file is, in fact, the employee information of a state. Here it is the data of the state of Missouri. Click

A7 works out the grouping and summarizing result of the 22nd group using groups function, that is, the number of employees from the state of Michigan:

It is thus clear that a sequence consisting of temporary cursor
files will be returned in grouping records of cursors using directly specified
group numbers. Each cursor file contains the records of a group and the data in
a cursor can be further processed.
2.Grouping and summarizing result sets of huge data
When grouping data of cursors, most of the time we needn't to know
the detailed data of each group. What we only need is to get the grouping and
summarizing result. To get the number of employees of each state from BirthStateRecord, for example, we use groups function to compute the grouping and summarizing result:

Thus we can get the result in A3:
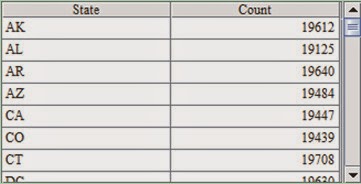
Here we notice that the groups function for grouping and summarizing will return a table sequence of the result after the computation is completed. In the operation of processing massive data, sometimes it is required to produce a great many groups and the result set of grouping and summarizing itself is too big to be returned. Such as the telecom company makes statistics of each customer's bill; online shopping malls make statistics by groups about the sales of each commodity, and the like. In these cases, the use of groups function may result in a memory overflow. We can use groupx(x:F,…;y:F,…;n) function instead to perform grouping and summarizing with the help of external memory. In the function, n represents the number of rows in buffer area. For example:

Still, the code is executed step by step until A4. In A3, groupx function uses external memory to perform grouping and summarizing. In cursor computing,groupx function is used in the operations of both grouping and summarizing with external memory and grouping by directly specified group numbers. The difference of the two operations lies in the parameters. A3 performs grouping by employees' birthdays, then summate the number of employees born each day. In the operation, the number of rows in buffer area is set as 1,000. The result returned by A3 is a cursor as follows:

After the code in A3 is executed, external files will be generated in the directory of temporary files:

The data of one of the temporary files can be imported:

The data A2 imports are as follows:

The data of A3 is as follows:

It can be seen that each temporary file is the grouping and summarizing
result of a part of the data obtained according to employees' birthdays. A
larger cursor composed of all temporary files will be merged
and returned by esProc. When the temporary files are generated, esProc will
select a group number suitable for computing, so the rows of data in the
temporary files will be a little more than the number of rows we set in buffer
area. Special attention is needed in this point.

No comments:
Post a Comment