
It is difficult for MongoDB to realize the operation
of cross summarizing. It is also quite complicated to realize it using
high-level languages, like Java, after the desired data is retrieved out. In
this case, you can consider using esProc to help MongoDB realize the operation.
The following example will teach you how it works in detail.
A collection – student – is given in the following:
db.student.insert ( {school:'school1', sname : 'Sean' , sub1:
4, sub2 :5 })
db.student.insert ( {school:'school1', sname : 'chris' , sub1:
4, sub2 :3 })
db.student.insert ( {school:'school1', sname : 'becky' , sub1:
5, sub2 :4 })
db.student.insert ( {school:'school1', sname : 'sam' , sub1: 5,
sub2 :4 })
db.student.insert ( {school:'school2', sname : 'dustin' , sub1:
2, sub2 :2 })
db.student.insert ( {school:'school2', sname : 'greg' , sub1:
3, sub2 :4 })
db.student.insert ( {school:'school2', sname : 'peter' , sub1:
5, sub2 :1 })
db.student.insert ( {school:'school2', sname : 'brad' , sub1:
2, sub2 :2 })
db.student.insert ( {school:'school2', sname : 'liz' , sub1: 3,
sub2 :null })
We are expected to produce a cross table as
the one in the following, in which each row is a school and the first column
holds students whose results of sub1 are a 5 and the second column holds those
whose results of sub1 are a 4 and so forth.

esProc script:
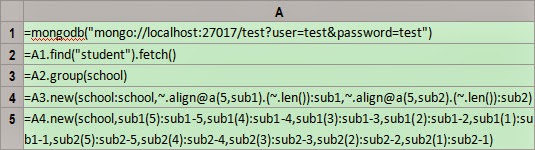
A1: Connect to MongoDB. Both IP and the
port number are localhost:27017. The
database name, user name and the password all are test.
A2: Use find
function to fetch the collection – student
- from MongoDB and create a cursor. Here esProc uses the same parameter format
in find function as that in find statement of MongoDB. As esProc's cursor
supports fetching and processing data in batches, the memory overflow caused by
importing big data all at once can thus be avoided. In this case, the data can
be fetched altogether using fetch
function because the size is not big.
A3: Group the data by schools.
A4: Then group each group of data in
alignment according to the sequence [1,2,3,4,5] and compute the length of each
subgroup.
A5: Put the lengths got in A4 into
corresponding positions as required and a record sequence wil be generated as
the result.
The result is as follows:
Note:esProc isn't equipped
with a Java driver included in MongoDB. So to access MongoDB using esProc, you
must put MongoDB's Java driver (a version of 2.12.2 or above is required for
esProc, e.g. mongo-java-driver-2.12.2.jar) into [esProc installation
directory]\common\jdbc beforehand.
The esProc script used to help MongoDB with
the computation is easy to be integrated into the Java program. You just need
to add another line of code - result A6
to output a result in the form of resultset
to Java program. For the detailed code, please refer to esProc Tutorial. In the same way, MongoDB's Java driver must be put
into the classpath of a Java program before the latter accesses MongoDB by
calling an esProc program.
No comments:
Post a Comment