
Programmers often encounter complicated
SQL-style computations during database application development. Record
splitting, for example, is to split a record separated by a certain separator
into multiple ones. For different databases, SQL has various problems like poor
syntax support and the need of writing nested and multilayered statements. esProc
boasts rich class library, has the ability to produce intuitive script step by
step and thus makes the handling of the case much easier. An example will be
used to illustrate how it works.
The application stores the operations of
each user at a single login in the user operation record table – user_op – by separating them with
commas. Some of the original data are as follows:
LOGTIME USERID OPID
2014/1/3 11:10:12 100001 a,d,h
2014/1/3 9:23:12 100002 a,e,g,p
2014/1/3 10:35:11 100003 a,r,n
Now we want to split each record separated
by commas into multiple ones. For instance the first record will become this
after splitting:
LOGTIME USERID OPID
2014/1/3 11:10:12 100001 a
2014/1/3 11:10:12 100001 d
2014/1/3 11:10:12 100001 h
SQL needs recursive queries to handle this
kind of operation, but it is extremely difficult when the database supports
recursion poorly. Even Oracle that supports recursion well has difficulty in
doing this. The following SQL statements are used to prove this point:
SELECT logtime,userid,REGEXP_SUBSTR(opid,'[^,]+',1,rn) opid
FROM user_op,(SELECT LEVEL rn FROM DUAL
CONNECT BY LEVEL<=(SELECT MAX(length(trim(translate(opid,replace(opid,','),' '))))+1 FROM user_op))
WHERE REGEXP_SUBSTR(opid,'[^,]+',1,rn) IS NOT NULL
FROM user_op,(SELECT LEVEL rn FROM DUAL
CONNECT BY LEVEL<=(SELECT MAX(length(trim(translate(opid,replace(opid,','),' '))))+1 FROM user_op))
WHERE REGEXP_SUBSTR(opid,'[^,]+',1,rn) IS NOT NULL
OR
select logtime,userid,regexp_substr(opid,'[^,]+',1,level) opid
from user_op
connect by level <= length(opid)-length(regexp_replace(opid,'[^,]+',''))
and rowid= prior rowid
and prior dbms_random.value is not null
from user_op
connect by level <= length(opid)-length(regexp_replace(opid,'[^,]+',''))
and rowid= prior rowid
and prior dbms_random.value is not null

In this
esProc script:
A1=esProc.query("SELECT
LOGTIME,USERID,OPID FROM USER_OP")
Retrieve data of user_op from the database. Part of the result is as follows:

A2= A1.create()
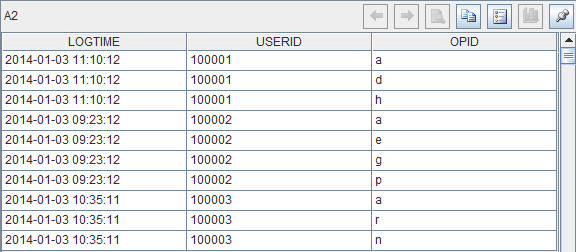
Based on A1, create a new table sequence with the same structure to store the final result set. The new table sequence is as follows:

A3=A1.(OPID.array().(A2.record([A1.LOGTIME,A1.USERID,~])))
Loop through each record of A1’s sequence table to split each value of OPID field and convert it into a sequence. Then write the splitting results to A2’s result set. The result of A2 is as follows:
It can be seen that esProc uses merely three lines of code to complete the record splitting operation. By the way, esProc can be called by the reporting tool or Java program much like they call a database, and provides JDBC interface to return the result in the form of ResultSet to Java main program. See related documents for details.
No comments:
Post a Comment